Optimized Task Scheduling Algorithm for Cloud Computing Environment
Info: 9885 words (40 pages) Dissertation
Published: 24th Jan 2022
Tagged: Information TechnologyComputing
Abstract
Cloud Computing is a rapidly growing technology and it offers online accessible resources to the users. These resources include applications, servers, networking, and storage etc. and provide security, elasticity, scalability and low cost. Another advantage of using cloud computing is users have to pay for only what they are using and users can access these resources on-demand. Most of the businesses are migrating from on-premise to the cloud and millions of users access these services daily via the internet. So it is very important to apply appropriate scheduling technique to process a large amount of data and to do resource utilization more efficiently with better performance.
This research paper presents new proposed algorithm which is using benefits of both Enhanced Max-Min and Max-Min algorithms together. In this proposed algorithm, there are two sets of resources created by considering their MIPS speed where the first one contains the resources with maximum execution time and the second one contains the resources with minimum execution time. The large task is assigned to the resource if the available resource is from the second set and average length task is assigned to the resource if the available resource is from the first set. The simulation tool used for testing is WorkflowSim. Test results display that the new proposed algorithm represents enhanced resource utilization with better makespan.
Contents
1. Introduction 3
2. Related Work 4
2.1 Problem Statement: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Task Scheduling Approaches:. . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 Cloud Simulator:……………………………………………10
3. Methodology 11
3.1 Proposed Methodology……………………………………………12
3.1.1 Simulation Tool…………………………………………….12
3.2 Design Specification……………………………………………..13
3.2.1 Pseudo Code……………………………………………….13
3.2.2 Workflow Diagram………………………………………….13
4. Implementation 15
5. Evaluation 16
5.1 Makespan Evaluation for 5 Virtual Machines:…………………………..17
5.2 Makespan Evaluation for 15 Virtual Machines:………………………….18
5.3 Makespan Evaluation for 30 Virtual Machines:………………………….20
5.4 Discussion…………………………………………………….21
6. Conclusion and Future Work 22
A Appendix: Configuration Manual 25
1 Introduction
Cloud computing is a new ordinary technology and becoming very famous among businesses, companies, institutions and industries. Cloud computing provides various on-demand IT resources which are accessible via internet and follows pay as you go model. That means users can access these resources whenever they want to use and pay for it as per usage. There is no need to pay for the resources which they are not using. Businesses uses these resources for various purposes such as for computing, storage etc. There are some advantages of cloud computing over the traditional computing technique. It provides agility, speed and flexibility that means users can scale up and scale down the service capacity as per the requirements. It also offers scalability that means users can add resources in case of increasing load and remove resources in case of decreasing load.
Cloud is also very secure as users can access data which is stored in a cloud from anywhere in the world and it also offers disaster recovery. On-premise services required initial purchase of software, hardware, licences etc. and it involves labour cost, patches and setup cost, upgrade cycles, fixed capacity. But in case of cloud, there is no need of upfront investment and on-going cost is also very less. Cloud take care of all the required infrastructure so that employees can focus on innovation instead of worrying about infrastructure.
There are main five characteristics of cloud computing such as on-demand self-service – user can access the required services by signing up without waiting so much, Resource pooling – resources are shared among several users, Measured service – use of resources is measured and billing of the usage is delivered, Broad network access users can access the resources through usual platforms like laptop, mobile phone etc., Rapid elasticity – user can scale the resource capacity to fulfil the increasing demands.
There are many cloud service providers in market which offers services from small to large businesses using three service models SaaS, PaaS and IaaS. SaaS means Software as a Service and it offers on-demand foundation for software which is accessible through web browser. User can access software remotely but user do not have control on infrastructure and platform. YouTube and Facebook are the example of SaaS.
PaaS means Platform as a Service and it offers an environment for application development using tools and programming languages supported by service providers. Users have control on deployed application but do not have any control on underlying infrastructure. Google app engine is the example of PaaS.
IaaS means Infrastructure as a Service and it offers whole virtualized data center to the user which includes computing, bandwidth, storage etc. resources. Amazon EC2 is the example of IaaS. Public cloud, private cloud, community cloud and hybrid cloud are the deployment models of cloud computing. General people can access the public cloud. Cloud service provider is the owner of a public cloud. It is not much secure as anyone can access it. Google app engine and AWS are the examples of public cloud. Private cloud is owned by the specific organization. It is more secure than a public cloud and organization have full control on data. Community cloud is used by the group of organizations having common requirements. It is used by organizations to achieve the same goal for example if they are working on the combined project. Hybrid cloud is the combination of two or more community, public and private clouds(Gouda et al.; 2014).
The user can share cloud resources using any device through internet. The internet is mandatory for accessing cloud services. The same resource is shared by multiple users virtually in a cloud. Cloud service providers, as well as users, are getting benefits from cloud computing. There are many companies renting cloud resources to decrease their cost of infrastructure. Billions of users are using cloud computing facility on daily basis.
So the number of data stored and handled in a cloud is very huge and this data amount is increasing day by day. Proper task scheduling technique is important to manage the large bunch of tasks that arrived in cloud concurrently. There is a need for better resource utilization to handle the large amount of load. Assignment of tasks to the resources is the task scheduling. It is necessary to allocate all the resources which are available for processing tasks instead of using few resources. It reduces the burden of resources while processing tasks.
Better scheduling technique is also useful for cloud providers to get more revenue. In a cloud, task scheduling and resource organization play an important role in effective resource management (Sindhu; 2015). There is not one uniform way of scheduling in cloud computing. Various task scheduling techniques already exist. But this research work presents proposed task scheduling algorithm reduces the total length of scheduling and utilizes resources properly.
The rest part of this research work is ordered in the following manner. Second section contains Related Work which presents study of various existing task scheduling algorithms and associated work. Third section contains Methodology which describes proposed task scheduling algorithm and design specification. Fourth section contains Implementation that presents all the information and steps regarding proposed scheduling algorithm implementation. Fifth section contains Evaluation that shows the findings and results analysis. Sixth section is the Conclusion contains outcome of the experiment.
2 Related Work
In this section we discuss relevant related research divided in the topics such as Problem statement, Task scheduling approaches, Cloud simulator.
2.1 Problem Statement
Task scheduling is a process in which tasks that need to be executed are assigned to the available resources in the cloud through the internet. If a provision of resources is not done appropriately, most of the cloud services remain unused. To fulfill the user demands and application requirements, the service provider uses Resource Allocation Policy which is the combination of all the actions that has been taken to allocate scarce resources. For this cloud service provider need to have an idea about how much and which type of resources are required to execute a particular task.
Before provisioning resources, a service provider should know about all available resources and also the status of each resource. Whereas user should know about all needs of the application. This is useful to escape from situations such as scarcity, fragmentation, and contention of resources as well as to avoid under and over provisioning. The problem will occur if more than one task makes effort to use the same resource simultaneously, limited set of resources are available as compared to user requirements or task is allocated to extra resources instead of assigning to exact one.
There is a necessity of proper resource management because users resource request is unpredictable for service provider and users are looking for the services which take less time and money to complete the task. There are two types of resources in cloud environment i.e. virtual and physical. Figure 1 shows the mapping of virtual to physical resources. Virtualization technology is used for assigning users task to the resources. These resources are distributed as per the user demand. Discovering efficient resource utilization technique is quite difficult in cloud computing (Vinothinaet al.; 2012). Task scheduling is a critical process because cloud service provider has to find a suitable way for scheduling the tasks arrived from users to the available resources within a given cloud environment.
The scheduling algorithm should be useful in increasing performance with a decrease in total execution time and completion time of tasks. There is a need for appropriate scheduling algorithm in grid and cluster computing because a large amount of data and computing processing has been done within that distributed environment. Cloud is a virtual pool of resources and services. At the same time, a large set of users sharing and accessing these cloud services to perform their jobs. Most of the people are using cloud services facility because it is less costly and there is no need to buy hardware and software, no need to do software installation every time as per application requirements. Cloud services save both money and time of end users.
Therefore, huge access of these facilities increases the load on a cloud system and so to balance such load situation it is the responsibility of service providers to choose suitable task scheduling method. Currently, various scheduling algorithms are in use which is mostly used to make task completion time shorter (Elzeki et al.; 2012).
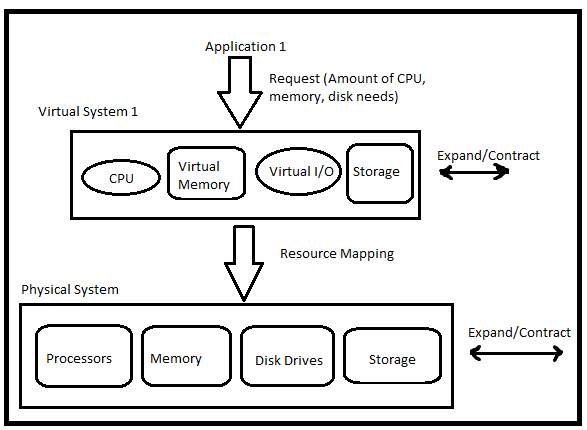
Figure 1: Mapping of virtual to physical resources (Vinothina et al.; 2012)
Cloud computing is used to deliver the online dynamic services with the help of virtualized resources. A number of available standard scheduling techniques are very few in cloud computing arena because of its newness. It is very difficult to apply popular job schedulers in the cloud environment because the cost of communication is very much. So that scholar is now working on the implementation of task scheduling algorithms which are appropriate and well-suited for massively distributed environment.
In the cloud, users pay to the service provider for how much time they are using particular services. Hence the effective process of scheduling a task has huge importance in the cloud computing. As well as better scheduling technique is useful for cloud service providers to gain high resource benefit. One of the main actions done in every computing technology is a task scheduling. A modern technology whose acceptance is increasing extremely is the cloud computing. Task scheduling plays an important role to get more profit by proficiently making growth in the processing of cloud environments. Task scheduling algorithm is used to utilize resources more efficiently while reducing the overall execution time of tasks and to distribute the total load on various computing resources. Task scheduling also plays the main role in the development of consistent and elastic systems.
Scheduling technique is used to map tasks to the flexible resources in compliance with resilient period and to discover the suitable execution order of tasks. Dynamic scheduling and static scheduling algorithms are the two key types of algorithms that are based on job scheduling. Each algorithm has some limitations as well as some advantages. The static scheduling algorithm has less overhead than dynamic scheduling algorithm whereas the performance of dynamic scheduling algorithm is much better as compared to the static scheduling algorithm. There is a lot of scheduling algorithms used in distributed environment at this point. After performing appropriate analysis, many of those algorithms are suitable for cloud systems.Task scheduling helps to get better throughput as well as enhanced performance. In cloud computing, there are two types of scheduling algorithms.
The first type is online mode heuristic scheduling algorithms and the second type is batch mode heuristic algorithms. Tasks are mapped to the resources immediately after the arrival of tasks in online mode heuristic scheduling. An example of this is the Most fit task scheduling. First Come First Serve(FCFS), Round robin, Max-Min are the examples of batch mode heuristic algorithms. It initializes the scheduling of tasks after a particular time period and it put all incoming tasks into the queue.
In the cloud, scheduling is done in three steps which are discovery and filtering of resource, selection of resource and mapping of the task. Figure 2 shows the scheduling process in cloud. Resources available in the system are discovered by Datacenter Broker and it also gathers the related information such as a status of the resource, etc. The second step is the selection of resource among all available resources and this selection is takes place by considering definite parameters of both resource and task. The last step is to map the task to the selected resource (Salot; 2013).
2.2 Task Scheduling Approaches
Next, we discuss various scheduling algorithms that help in reducing the total length of scheduling. We start our study with traditional algorithm First Come First Serve(FCFS). This scheduling algorithm schedule the tasks on a first come first serve basis. This is the fast and simplest algorithm. Round Robin algorithm uses the time-sharing technique while scheduling the tasks. The particular time slice is assigned to each task. This time slot is nothing but the CPU time. If selected task became unable to complete its execution within given CPU time, then next task in the ready queue is assigned to preempted CPU and a previous uncompleted task is pushed at the end of the ready queue. Small tasks took more time for execution in Round Robin algorithm because they share the CPU time with large tasks instead of they complete execution quickly (Salot; 2013). Minimum execution time(MET) algorithm is mostly used to reduce the total execution time of each task within a heterogeneous environment.

Figure 2: Scheduling Process in Cloud (Salot; 2013)
In some cases, a set of the various type of resources are required to perform a task and that time all the assigned resources should be matched with the application needs. Mapping of application to resources is NP problem. For efficient resource utilization, it is also necessary to know in which order task would be executing. MET algorithm uses first come first serve technique while assigning resources (Hemamalini and Srinath; 2015). MET select a resource which will execute the arrived task in less time as compared to all other resources. But it does not consider whether the selected resource is currently available to perform a task or not (Etminani et al.; 2009). This is increasing a load on cloud services. Task has to wait until the assigned resource becomes free.
Minimum Completion Time (MCT) algorithm is used for assigning submitted application to the resource which is able to complete the particular task with less time. In short, MCT selects the resource having minimum completion time but this algorithm works on tasks one by one (Moharana et al.; 2013). When a task is submitted by the user, opportunistic load balancing (OLB) algorithm find out the available resource and assign a task to it. If no resource is available at a current time, then OLB assign a task to the resource which will become free first and if there are a group of available resources, OLB select any resource randomly to assign a task
Hence there is a possibility of scheduling task to the resource which takes more time for execution and completion Maheswaran et al. (1999). Min-Min algorithm is used to perform tasks first which takes less time for completion. Therefore, huge tasks stay in queue until all small tasks finished their execution (Salot; 2013). Initially, all the tasks are not mapped to the resources. Consider that there are three tasks, Min-Min algorithm first calculates the completion time of each task on each resource.
Completion time is calculated by adding estimated execution time and available time of the machine. Then the resource which takes less time for completion of all the task is selected. After that task with less completion time among all other tasks is mapped to the resource. Next task is assigned to the same resource after execution of the previous one. Available time of the resource is modified for each task. Assignment of task continues until all tasks get completed (Sindhu; 2015).
Max-Min algorithm is used to perform tasks first which takes more time for completion. Therefore, small tasks stay in queue until all huge tasks finished their execution (Salot; 2013). Similar to Min-Min algorithm, all the tasks are not scheduled at first. A resource which takes minimum time for task completion is chosen. Then the task with large completion time is mapped to the selected resource. All the large tasks are executed first. Therefore, large tasks do not have to wait for a long time for execution.
Mapping of tasks to resource continues until all tasks executed. Like Min-Min, available time of the machine is also modified. For example, if the first task requires 80 seconds for completion, then execution time of remaining tasks are increased by 80 seconds (Sindhu; 2015). Resource Aware Scheduling Algorithm (RASA) provides benefits of both Min-Min and Max-Min algorithm. RASA is used to schedule a task based on either Min-Min or Max-Min according to the current situation. Selecting small task first and mapping it to the fast resource is the work of Min-Min algorithm.
This type of scheduling is useful when there are less number of small tasks than large tasks. If submitted task contains only one large task and all other are small tasks, then using Min-Min algorithm will increase total make-span because the large task executed at last after completion of all tasks. In such situations, using Max-Min algorithm is a beneficiary. This algorithm allows the large task to be executed first and during execution of large tasks, set of small tasks can be executed simultaneously. Executing large tasks first may result in high response time.
RASA algorithm provides advantages of choosing suitable algorithm either Min-Min or Max-Min alternatively at any stage of scheduling. For example, if there are all small tasks initially then RASA prefer Min-Min algorithm for scheduling task to a resource. But if one very large task arrived suddenly, then RASA will change the preference to Max-Min algorithm for task completion. Some tests have proven that better scheduling happens when using Max-Min technique if there are an even number of available resources initially otherwise using Min-Min technique. This algorithm increases efficiency and produces better response time (Parsa and Entezari-Maleki; 2009).
Heterogeneous Earliest Finish Time algorithm is popular for giving a better result within a less time. It is a static scheduling algorithm. HEFT heuristic is more useful among all other heuristics because of it provides good scheduling within a heterogeneous environment with less time. HEFT works in two stages. In the first stage, HEFT set priority for all submitted tasks and in the second stage, choose the task with the highest priority and assign it to the resource which finishes execution process early. After completion of the first task, this process is repeated for all the remaining tasks.
Each task is assigned to the best resource which results in earliest finish time (Topcuoglu et al.; 2002). For setting the priority of each task, HEFT first computes how much execution time will require for each submitted task. It also computes time required to transfer result between the resources if there are some tasks which are dependent on each other for completion. HEFT offers great performance and speed (Bittencourt et al.; 2010).
As explained earlier that Max-Min algorithm first chooses a resource which takes less time for task completion and then long task i.e. a task takes maximum time for execution is selected and assigned to that resource. But, in improved Max-Min algorithm, a task having large completion time is mapped to the resource which will execute the assigned task with less time. Advantages of using this algorithm are all arrived small tasks are executed simultaneously with the long task. This will reduce the total length of scheduling and total execution time as compared to Max-Min algorithm.
It also allocates all available resources more precisely to handle the increased load on the system than Max-Min (Rajwinder Kaur; 2014). In improved Max-Min algorithm, it first selects the task with extreme execution time among all arrived tasks and scheduled it to the slowest resource. But this is not useful every situation. What if there is a very large task as compared to all other tasks and if that long task mapped to slow resource, it will increase make-span as well as load. Enhanced Max-Min algorithm provides the solution to such situations. Instead of choosing long task first, it selects medium length task and assigned it to the resource having less completion time. So that fast resources are available to handle the largest task as well as all small tasks at the same time.
This algorithm reduces the total make-span and increases the performance as compared to improved Max-Min algorithm. But if the long task is mapped to the slow resource which still results in the increase in total length of scheduling (Bhoi and Ramanuj; 2013).
In the cloud infrastructure, Resource management system is a vital part of computing because of the current large-scale data centers. In the cloud, a single user can get access to multiple resources at the same time. So the major contest is to agree on how many users can manage on a single resource. (Sviji; 2016) describes actual resource management system. The job of resource management system is to manage resources in the cloud and it is the deepest procedure in the cloud.
Resource management system offers a variety of services and it receives resource requirements and allocates fixed amount of resources among a set of resources to the requested users. There are main two types of resource management system, one is local resource management system where an ordinary interface is available to use distant resources and second is global resource management system where local resource management systems are organized within virtualized organization to access and handle resources (Sviji; 2016).
Resource allocation strategy is the combination of all actions of service providers to fulfill the requirements of cloud application by assigning rare resources. It is important to identify which type of and how many resources are required to execute the task. To get ideal resource allocation strategy, it is necessary to provide resource assignment sequence and time as an input.
Best resource allocation strategy is vital to avoid under provisioning, over provisioning, resource contention, resource fragmentation and scarcity of the resource. In the case of under-provisioning, only a few resources are allocated to the application than it actually required. Under-provisioning happens due to the assignment of resources by the cloud service providers. In a case of over provisioning, there is a set of extra resources available than the what application exactly required for completion.
Over-provisioning happens due to the guess of users about total requirements of resources to fulfill the task within estimated time period. Resource contention means that conflict occurs while accessing shared resources like storage, memory. This problem happens when multiple users want to access shared resource. It causes low system performance.
In Resource fragmentation, a user is not able to get access to resources although there are sufficient resources available because resources are fragmented into the small objects. So that it is not possible to utilize such resources ideally. The scarcity of Resource means that demand for resources is so high as compared to the actual available resources.
In this case, a user can not access the required resources. Therefore, resource allocation strategy should get input from the user as well as from the service provider to avoid above stated inconsistencies. From the users point of view, the main inputs to the resource allocation strategy are service level agreement and needs of the application. Cloud service providers give input such as a status of resource, provisioning, resource availability to the resource allocation strategy for the assignment of resources to the given tasks. Resource allocation strategy is ideal when it provides better response time, latency and throughput (Sagar et al.; 2013).
Load balancing is done at two stages in cloud computing, first one is while assigning applications to the physical computers for balancing a load on it and the second one is while assigning multiple requests to the application instances for balancing a load on applications. Although resources offered by the cloud are reliable but it causes some difficulties during resource management and allocation. From the service providers point of view, it is unfeasible to guess the demands of application and demands of users. Users want to finish a task with less time and cost. Therefore, cloud requires effective resource allocation method (Babu and Kumar; n.d.).
In task scheduling, the task first comes to cloud coordinator. Cloud coordinator send this task to the data center. There are lots of hosts in a data center which contains many virtual machines. It is possible to organize and remove the host according to demand (Warneke and Kao; 2011). In the process of resource allocation, virtual machine manager forward needs of a task to the service provider and request for resources as per requirements. Service provider asks resource owner whether the requested resources are available or not. Then provider gets approval of accessing available resources from resource owner. The service provider also provisions resources to create virtual machines. The virtual machine is nothing but a virtualized server(Cao et al.; 2009).
Virtualization plays an important role in cloud computing. There is one hypervisor layer called virtual machine monitor located between the operating system and hardware in case of system virtualization. The system consists of the network of virtual machines where live migration among infrastructure is possible. The virtual machine is capable of scaling up or down the resources. Virtualization is used to create a view of multiple logical servers from one physical server where each server having a separate guest operating system or to create a logical view of multiple virtualized storages from single physical storage(Sagar et al.; 2013). Users having requirement of different operating systems are able to access virtualized server as the operating system.
There are many advantages of virtualization such as better use, reliability, security, and management (Priyadarsini and Arockiam; 2014). Initially, implementation of scheduling algorithms is done in grids because of their low performance. Now the same thing is happening in the cloud (Tilak and Patil; 2012). Scalability is the main reason for migrating to cloud. Cloud computing permits to access real-time resources to fulfill application needs which are not possible in grids (Priyadarsini and Arockiam; 2014).
2.3 Cloud Simulator
WorkflowSim is the toolkit used for simulation of scheduling algorithms. It is the advanced version of CloudSim by offering better workflow management and accurate evaluation. CloudSim (Calheiros et al.; 2011) is used for simulation of cloud services and infrastructure. CloudSim allows executing only single workload. It does not consider failures and overheads. It does not support clustering and job dependencies. Unlike other simulators, failures and overheads occurred in the heterogeneous system are considered into the WorkflowSim.
It also supports clustering. Figure 3 shows the WorkflowSim Architecture. WorkflowSim contains multiple layers such as Failure monitor, Failure generator, Clustering engine, Workflow engine and Workflow mapper along with the Workflow scheduler which is present into the CloudSim.
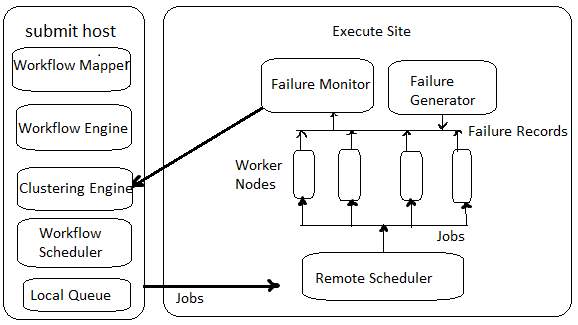
Figure 3: WorkfowSim Architecture (Chen and Deelman; 2012)
Workflow mapper has used for mapping non-concrete workflows to the actual workflows which are reliant on execution sites. Data dependencies are managed by Workflow engine. Tasks are scheduled to the resources with the help of Workflow Scheduler. Small jobs are combined into a large one by using Clustering engine (Chen and Deelman; 2012).
3 Methodology
We have studied various task scheduling algorithms in literature review section. Each algorithm has its own benefits and limitations. Some algorithms are implemented to overcome some limitations of the previously existing algorithm. For example, the limitation of Min-Min algorithm is large task may have to wait for execution until all task gets finished. But Max-Min algorithm is implemented to overcome such problem to get better performance than Min-Min algorithm. Max-Min algorithm executes long tasks first, so that it may effect on total response time. Resource Aware Scheduling Algorithm is another approach which allow the system to use both Min-Min and Max-Min techniques alternatively so that to get proper load balancing and enhanced response time.
Enhanced Max-Min algorithm is useful in a situation like if there is a very long task among all arrived tasks, then giving a resource to it first will increase a make-span i.e. total length of scheduling. So the solution offered by Enhanced Max-min is to choose a task which is average in length and assigning it to the fast resource. Whereas Heterogeneous Earliest Finish Time algorithm assigns highest priority task to the resource which will finish it in less time. But all above algorithms still faces the one problem when a long task may have mapped to the resource which takes much time for execution results in increasing length of scheduling i.e. makespan. To overcome this problem we propose an algorithm which reduces the makespan.
3.1 Proposed Methodology
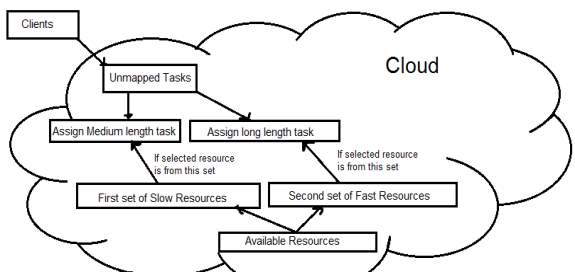
Figure 4: System Architecture
Our proposed approach divides all available resources into two sets where first set is of the slow resources and second set is of the fast resources. This partitioning is done according to the MIPS speed of each resource. Suppose that there are 10 available resources. The first step is to sort these resources into ascending order by considering their MIPS speed and then add first 5 resources into the first set and remaining 5 resources into the second set. Figure 4 shows the overall view of our solution. When tasks arrived for execution, choose the resource which takes less time for execution among all available resources before assigning any task. If chosen resource is from the first set, then assign average length task to it and if chosen resource is from the second set, then assign the longest task to it.
The technique used in proposed algorithm for scheduling tasks is the combination of both Max-Min as well as Enhanced Max-Min. The proposed algorithm minimize the chances of scheduling a large task to the slow resource with making completion time shorter. In short, Proposed algorithm helps to utilize resources more efficiently and achieve good performance in terms of makespan as compared to existing algorithms.
3.1.1 Simulation Tool
This research project uses WorkflowSim. It is very popular for simulation purpose. It is the enhanced version of CloudSim.. There are many simulation tools are available such as GridSim, CloudSim, WorkflowSim. But we chose WorkflowSim as a cloud simulator because it offers workflow level support and clustering. But GridSim and CloudSim do not support clustering and also do not consider overheads. WorkflowSim is a simulation framework to test and validate the accuracy of the proposed algorithm (Chen and Deelman; 2012). WorkflowSim is open source toolkit written in Java.
3.2 Design Specification
This section presents the pseudo code and workflow diagram of the proposed algorithm.
3.2.1 Pseudo Code
The proposed solution is given below and it shows working of algorithm step by step. When it comes to performance, it is the responsibility to choose better task scheduling method which gives advantages like proper load balancing, less make-span, minimum completion time. To achieve all these, it is important to utilize all resources effectively. The proposed algorithm is the combination of Enhanced Max-Min and Max-Min strategies. When using these strategies separately, it generates problem like delay in large task completion, response time issues. But if we use these strategies combine, it will prove beneficiary in terms of performance and makespan.

Algorithm 1: Proposed Algorithm
3.2.2 Workflow Diagram
Workflow diagram is basically used to symbolize overall process into steps. It depicts how the algorithm works. Block is used for each individual action. All the actions are connected through arrows. Arrows helps to represent where the flow goes and what is the order of the whole process. A rectangular box is used to indicate activity and diamond is used to make a decision. This flow chart represents all activities such as sorting, dividing, and selection of resource, task assignment criteria etc.
These steps are useful for the easy understanding of concept or algorithm. Client or user send tasks for execution. Initially, all tasks are unmapped. Then sorting resources and partitioning them into two sets. Find out the resource having minimum execution time. If this resource found out in the first set, assign medium size task to it else assign the large task. After completion of task execution, release that resource and make it available for other tasks. The same process repeats until all tasks finished.
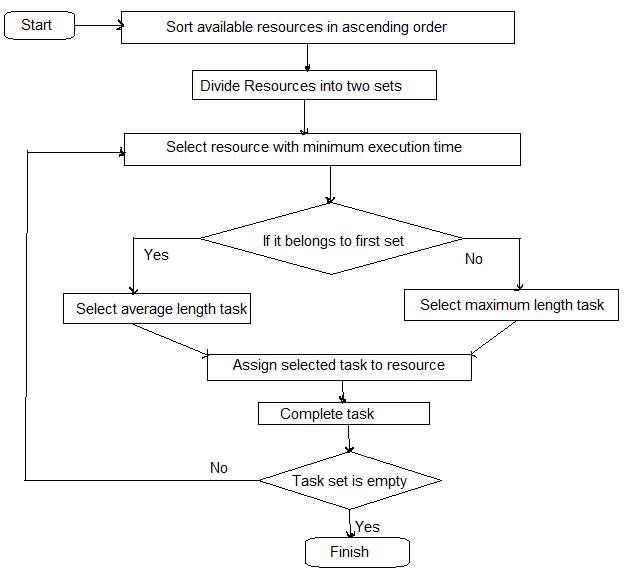
Figure 5: Workflow Diagram
4 Implementation
This section contains the implementation part of this research that means development and simulation process of the proposed algorithm using WorkflowSim tool as well as software and hardware requirements for this experiment.
The software used for this experiment are Eclipse Java Neon and WorkflowSim 1.0. The configuration of the system used for this experiment are 64-bit Windows 10 operating system, Intel(R) Core(TM) i5 CPU 2.20 GHz, 8GB RAM. We have developed the proposed algorithm in Java language. Then WorkflowSim simulator is used to test the developed algorithm. It offers workflow level support during the simulation. To test the proposed algorithm, one data center, one scheduler, and 5 virtual machines are used first. Then Proposed algorithm tested by using five workflows named Maontage50, Montage100, CyberShake30, CyberShake50,and Inspiral50. The reason behind choosing these workflows for testing is that previous research papers (Haladu and Samual; n.d.),(Konjaang et al.; 2016) have used these datasets to test MaxMin algorithm.
The purpose of this paper is to show that performance of proposed algorithm is better than the MaxMin algorithm. Then the number of virtual machines are increased by 15 and 30 respectively to test the algorithm on the same workflows as mentioned above. There is one DAX file in WorkflowSim which contains all the workflows. All these workflow files are in .xml format. There are a maximum number of large tasks in Montage workflow. Montage50 contains total 50 tasks and Montage100 contains total 100 tasks. There are less number of large tasks in Inspiral workflow.
Inspiral50 contains total 50 tasks. Large sized tasks in CyberShake are in average numbers. CyberShake30 means it contains 30 tasks and CyberShake50 means it contains 50 tasks (Brar and Rao; 2015). We have also developed FCFS and MaxMin algorithms in Java using their pseudo codes for the simulation purpose. Because we compares our proposed algorithm with FCFS and MaxMin to check whose performance is better. Figure 6 shows the high-level overview of the experimental setup.
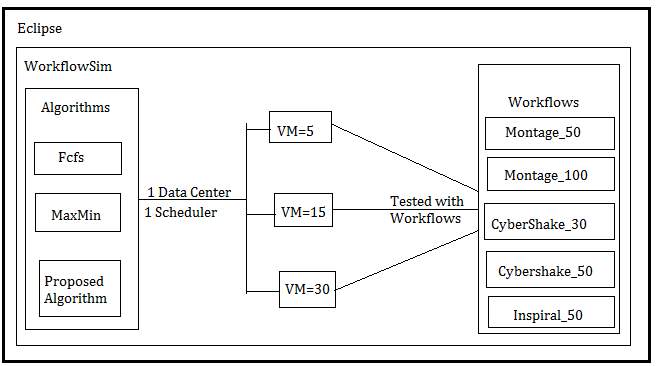
Figure 6: High-level Overview of Experimental Setup
We use several WorkflowSim components such as Workflow Mapper, Clustering Engine, Workflow Engine, Workflow Scheduler. They plays an important role during execution of each workflow. Figure 7 shows their interaction. Next, we provide description per each component.
Workflow Mapper: The job of Workflow Mapper is to import workflow file which is in the format of XML. Listing of tasks and then mapping are done by Workflow Mapper. Clustering Engine: The overhead of scheduling is minimized with the help of Clustering Engine by merging tasks into the jobs. A job is a unit recognized by execution site and it includes a number of tasks that are performed in parallel or in the sequence that means horizontal clustering or vertical clustering.
Workflow Engine: Jobs created during clustering are handled and managed by Workflow Engine. Workflow Engine forward job to the scheduler only if all the previously released jobs have executed well.
Workflow Scheduler: Scheduling of jobs to the worker nodes are done by Workflow Scheduler. Worker node should be ideal for the process of scheduling jobs to it in the remote scheduler.
These components are coordinated with each other by managing their own message queue. That means for every iteration, Clustering Engine review if it needs to forward a job to the scheduler or if Workflow Engine has sent tasks to it. The simulation got over if message queue of all the components is empty (Chen and Deelman; 2012).
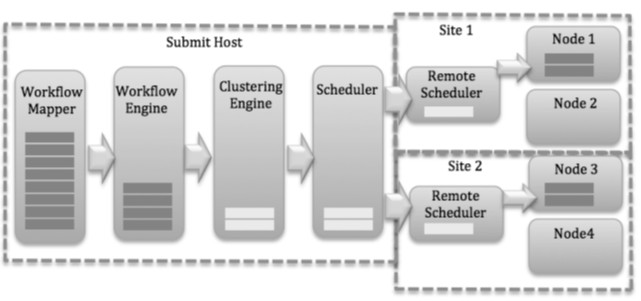
Figure 7: Interaction between WorkflowSim Components (Chen and Deelman; 2012)
5 Evaluation
In this section, we want to validate that proposed algorithm behaves better. We have conducted several experiments to test the performance of proposed algorithm in terms of makespan and this section also shows performance comparison between the proposed algorithm and two existing scheduling algorithms FCfS and MaxMin. One data center and one scheduler is used for the simulation. Number of virtual machines used for simulation are 5, 15 and 30. Number of virtual machines are increased per evaluation to check the performance of proposed algorithm in each environment. During each evaluation, proposed algorithm has tested ten times for each workflow Montage50, Montage100, CyberShake30, CyberShake50 and Inspiral50. Then for each workflow, the output of all ten tests are stored into excel file. Then listed out makespan of all ten tests and then took the median of it. This median is the final makespan of proposed algorithm for the tested workflow. The makespan of existing algorithms FCFS and MaxMin for each workflow have calculated in the same way. Below subsections shows the results of each evaluation.
5.1 Makespan Evaluation for 5 Virtual Machines
There are total 5 virtual machines are used for this evaluation. Table 1 shows the performance comparison between the proposed algorithm, FCfS, and MaxMin with respect to makespan using different workflows. Figure 8 shows the graphical representation of the results where VM = 5.
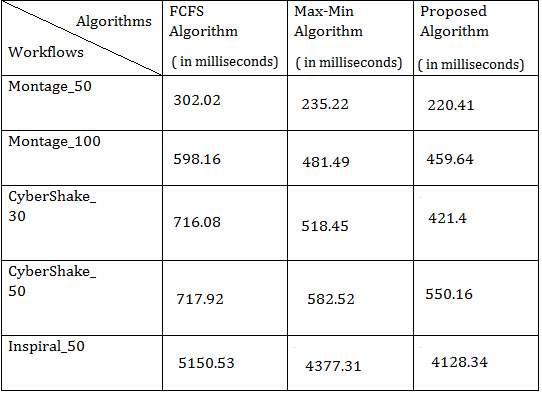
Table 1: Makespan Comparison of Scheduling Algorithms where VM=5
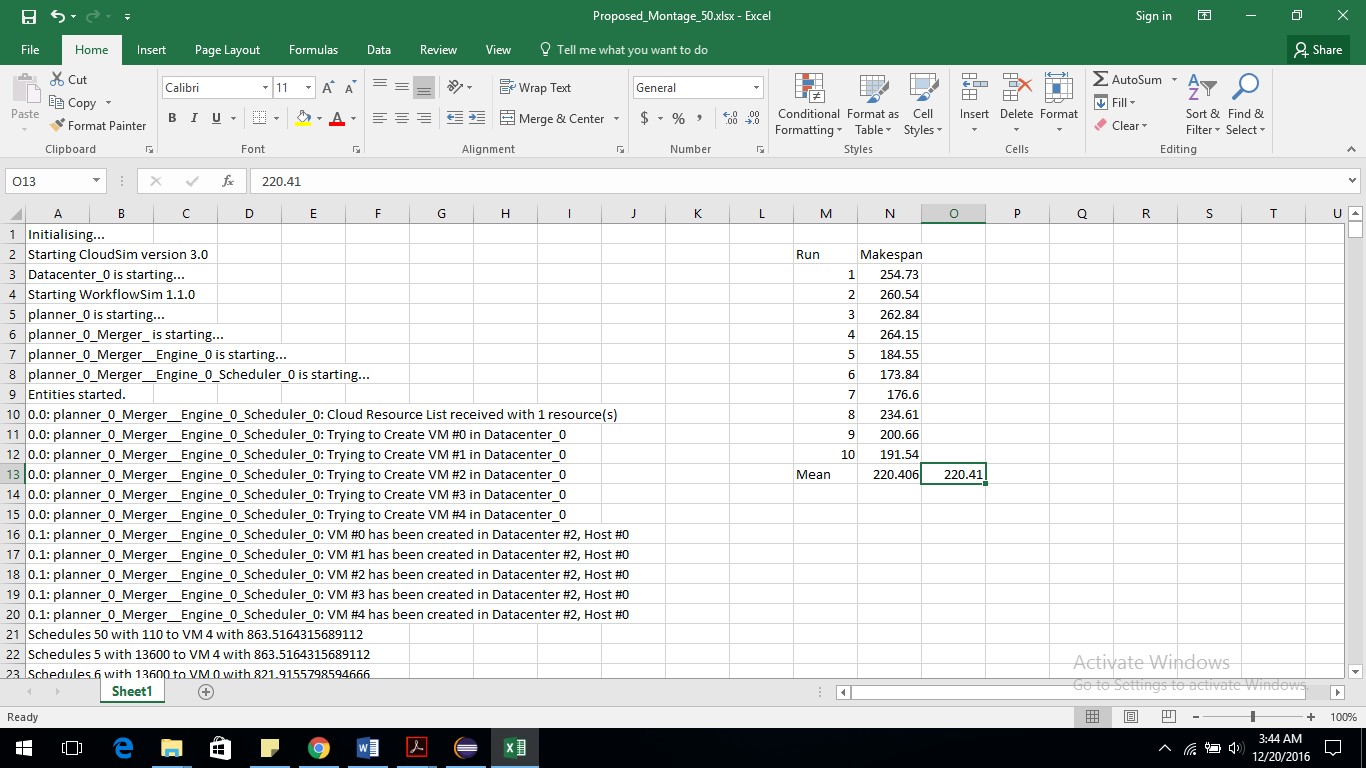
The results shows that makespan of proposed algorithm for Montage50 workflow is 220.41 milliseconds(ms) which is less than the makespan of FCFS= 302.02 ms and MaxMin= 235.22 ms. Performance of proposed algorithm is around 6 percentage better than the MaxMin and around 27 percentage better than the FCFS for workflow Montage50. Makespan of proposed algorithm for Montage100 is 459.64 ms which is less than the makespan of FCFS= 598.16 ms and MaxMin= 481.49 ms.
Performance of proposed algorithm is around 5 percentage better than the MaxMin and around 24 percentage better than the FCFS for workflow Montage100. Makespan of proposed algorithm for CyberShake30 is 421.4 ms which is less than the makespan of FCFS= 716.08 ms and MaxMin= 518.45 ms. Performance of proposed algorithm is around 20 percentage better than the MaxMin and around 42 percentage better than the FCFS for workflow CyberShake30. Makespan of proposed algorithm for Cybershake50 is 550.16 ms which is less than the makespan of FCFS= 717.92 ms and MaxMin= 582.52 ms.
Performance of proposed algorithm is around 6 percentage better than the MaxMin and around 24 percentage better than the FCFS for workflow CyberShake50. Makespan of proposed algorithm for Inspiral50 is 4128.34 ms which is less than the makespan of FCFS= 5150.53 ms and MaxMin= 4377.31 ms. Performance of proposed algorithm is around 6 percentage better than the MaxMin and around 20 percentage better than the FCFS for workflow Inspiral50.
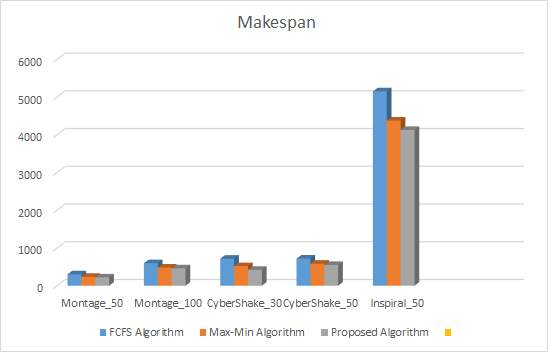
Figure 8: Makespan Comparison of Scheduling Algorithms where VM=5
5.2 Makespan Evaluation for 15 Virtual Machines
There are total 15 virtual machines are used for this evaluation. Table 2 shows the performance comparison between the proposed algorithm, FCFS, and MaxMin with respect to makespan using different workflows. Figure 9 shows the graphical representation of the results where VM = 15.
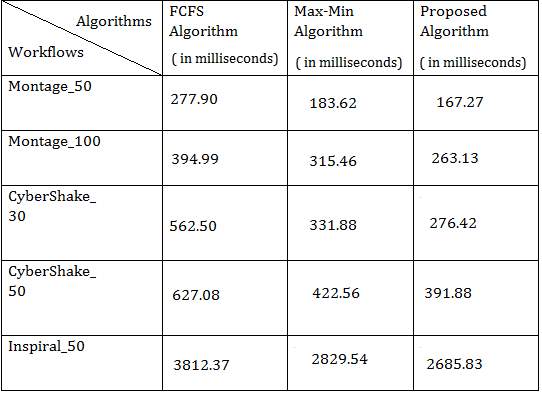
Table 2: Makespan Comparison of Scheduling Algorithms where VM=15
Figure 9: Makespan Comparison of Scheduling Algorithms where VM=15
The results shows that makespan of proposed algorithm for Montage50 workflow is 167.27 ms which is less than the makespan of FCFS= 277.90 ms and MaxMin= 183.62 ms. Performance of proposed algorithm is around 9 percentage better than the MaxMin and around 40 percentage better than the FCFS for workflow Montage50. Makespan of proposed algorithm for Montage100 is 263.13 ms which is less than the makespan of FCFS= 394.99 ms and MaxMin= 315.46 ms. Performance of proposed algorithm is around 17 percentage better than the MaxMin and around 33 percentage better than the FCFS for workflow Montage100. Makespan of proposed algorithm for CyberShake30 is 276.42 ms which is less than the makespan of FCFS= 562.50 ms and MaxMin= 331.88 ms.
Performance of proposed algorithm is around 17 percentage better than the MaxMin and around 51 percentage better than the FCFS for workflow CyberShake30. Makespan of proposed algorithm for Cybershake50 is 391.88 ms which is less than the makespan of FCFS= 627.08 ms and MaxMin= 422.56 ms. Performance of proposed algorithm is around 8 percentage better than the MaxMin and around 38 percentage better than the FCFS for workflow CyberShake50. Makespan of proposed algorithm for Inspiral50 is 2685.83 ms which is less than the makespan of FCFS= 3812.37 ms and MaxMin= 2829.54 ms. Performance of proposed algorithm is around 5 percentage better than the MaxMin and around 30 percentage better than the FCFS for workflow Inspiral50.
5.3 Makespan Evaluation for 30 Virtual Machines
There are total 30 virtual machines are used for this evaluation. Table 3 shows the performance comparison between the proposed algorithm, FCFS, and MaxMin with respect to makespan using different workflows. Figure 10 shows the graphical representation of the results where VM = 30.
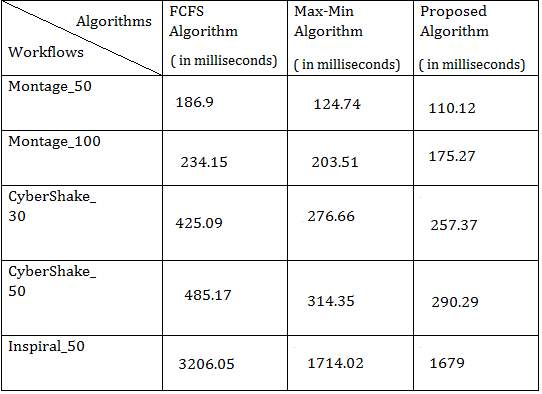
Table 3: Makespan Comparison of Scheduling Algorithms where VM=30
The results shows that makespan of proposed algorithm for Montage50 workflow is 110.12 ms which is less than the makespan of FCFS= 186.9 ms and MaxMin= 124.74 ms. Performance of proposed algorithm is around 12 percentage better than the MaxMin and around 41 percentage better than the FCFS for workflow Montage50. Makespan of proposed algorithm for Montage100 is 175.27 ms which is less than the makespan of FCFS= 234.15 ms and MaxMin= 203.51 ms. Performance of proposed algorithm is around 14 percentage better than the MaxMin and around 26 percentage better than the FCFS for workflow Montage100.
Makespan of proposed algorithm for CyberShake30 is 257.37 ms which is less than the makespan of FCFS= 425.09 ms and MaxMin= 276.66 ms. Performance of proposed algorithm is around 8 percentage better than the MaxMin and around 40 percentage better than the FCFS for workflow CyberShake30. Makespan of proposed algorithm for Cybershake50 is 290.29 ms which is less than the makespan of FCFS= 485.17 ms and MaxMin= 314.35 ms. Performance of proposed algorithm is around 8 percentage better than the MaxMin and around 40 percentage better than the FCFS for workflow CyberShake50. Makespan of proposed algorithm for Inspiral50 is 1679 ms which is less than the makespan of FCFS= 3206.05 ms and MaxMin= 1714.02 ms. Performance of proposed algorithm is around 5 percentage better than the MaxMin and around 48 percentage better than the FCFS for workflow Inspiral50.
Figure 10: Makespan Comparison of Scheduling Algorithms where VM=30
5.4 Discussion
Results of above evaluations show that proposed algorithm completes tasks execution with lower makespan and higher performance as compared to scheduling algorithms MaxMin and FCFS. Performance of proposed algorithm is around 8 percentage better than MaxMin algorithm and around 27 percentage better than FCFS for 5 virtual machines. Performance of proposed algorithm is around 10 percentage better than MaxMin algorithm and around 38 percentage better than FCFS for 15 virtual machines. Performance of proposed algorithm is around 10 percentage better than MaxMin algorithm and around 39 percentage better than FCFS for 30 virtual machines. Results shows that proposed algorithm behaves better in terms of makespan after testing it with Montage50, Montage100, CyberShake30, Cybershake50 and Inspiral50 workflows. As we increased a number of virtual machines which are used for simulation, still the total length of scheduling for the proposed algorithm is less than the MaxMin and FCFS.
6 Conclusion and Future Work
This research paper presents new task scheduling algorithm based on resource partitioning to minimize the total length of scheduling and proper resource utilization. This algorithm is implemented using WorkflowSim simulation tool. Large task is assigned to the fastest resource in case of MaxMin algorithm. There is a limitation of MaxMin which is sometimes large task is mapped to the slow resource. This increases the total length of scheduling. But in proposed algorithm possibility of scheduling long length tasks to the slow resource is reduced. Solution used in this paper is division of resources into two groups according to MIPS speed. If the fastest available resource is from the second group which is the group of fast resources, then the largest task is scheduled to it. If the fastest available resource is from the first group which is the group of slow resources, then the average length task is mapped to it. Results shows that proposed algorithm done efficient resource utilization and has better makespan than existing scheduling algorithms MaxMin and FCFS.
Overall result shows that the proposed algorithm performs better than MaxMin algorithm when it comes to makespan. Proposed algorithm improves the performance of scheduling by 10 percentage as compared to MaxMin. Makespan of proposed algorithm for all workflows such as Montage50, Montage100, CyberShake30, CyberShake50, and Inspiral50 is less than makespan of MaxMin.
References
Babu, K. D. and Kumar, D. G. (n.d.). Allocation strategies of virtual resources in cloud computing networks, Journal Of Engineering Research And Applications 201: 51–55.
Bhoi, U. and Ramanuj, P. N. (2013). Enhanced max-min task scheduling algorithm in cloud computing, International Journal of Application or Innovation in Engineering and Management 2(4): 259–64.
Bittencourt, L. F., Sakellariou, R. and Madeira, E. R. (2010). Dag scheduling using a lookahead variant of the heterogeneous earliest finish time algorithm, 2010 18th Euromicro Conference on Parallel, Distributed and Network-based Processing, IEEE, pp. 27–34.
Brar, S. S. and Rao, S. (2015). Optimizing workflow scheduling using max-min algorithm in cloud environment, International Journal of Computer Applications 124(4).
Calheiros, R. N., Ranjan, R., Beloglazov, A., De Rose, C. A. and Buyya, R. (2011). Cloudsim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms, Software: Practice and Experience 41(1): 23–50.
Cao, Q., Wei, Z.-B. and Gong, W.-M. (2009). An optimized algorithm for task scheduling based on activity based costing in cloud computing, 2009 3rd International Conference on Bioinformatics and Biomedical Engineering, IEEE, pp. 1–3.
Chen, W. and Deelman, E. (2012). Workflowsim: A toolkit for simulating scientific workflows in distributed environments, E-Science (e-Science), 2012 IEEE 8thInternational Conference on, IEEE, pp. 1–8.
Elzeki, O., Reshad, M. and Elsoud, M. (2012). Improved max-min algorithm in cloud computing, International Journal of Computer Applications 50(12).
Etminani, K., Naghibzadeh, M. and Yanehsari, N. R. (2009). A hybrid min-min max-min algorithm with improved performance, Department of Computer Engineering, University of Mashad .
Gouda, K., Patro, A., Dwivedi, D. and Bhat, N. (2014). Virtualization approaches in cloud computing, International Journal of Computer Trends and Technology (IJCTT).
Haladu, M. and Samual, J. (n.d.). Optimizing task scheduling and resource allocation in cloud data center, using enhanced min-min algorithm, IOSR Journals (IOSRJournal of Computer Engineering) 1(18): 18–25.
Hemamalini, M. and Srinath, M. (2015). Memory constrained load shared minimum execution time grid task scheduling algorithm in a heterogeneous environment, Indian Journal of Science and Technology 8(15).
Konjaang, J. K., Maipan-uku, J. and Kubuga, K. K. (2016). An efficient max-min resource allocator and task scheduling algorithm in cloud computing environment, arXiv preprint arXiv:1611.08864 .
Maheswaran, M., Ali, S., Siegel, H. J., Hensgen, D. and Freund, R. F. (1999). Dynamic mapping of a class of independent tasks onto heterogeneous computing systems, Journal ofparallelanddistributedcomputing59(2): 107–131.
Moharana, S. S., Ramesh, R. D. and Powar, D. (2013). Analysis of load balancers in cloud computing, International Journal of Computer Science and Engineering 2(2): 101–108.
Parsa, S. and Entezari-Maleki, R. (2009). Rasa: A new task scheduling algorithm in grid environment, World Applied sciences journal 7: 152–160.
Priyadarsini, R. J. and Arockiam, L. (2014). Performance evaluation of min-min and max-min algorithms for job scheduling in federated cloud, International Journal of ComputerApplications(0975–8887)Volume.
Rajwinder Kaur, P. L. (2014). Load balancing in cloud system using max min and min min algorithm, NationalConferenceonEmergingTrendsinComputerTechnology (NCETCT-2014) pp. 31–34.
Sagar, M. S., Singh, B. and Ahmad, W. (2013). Study on cloud computing resource allocation strategies, International Journal 1(3): 107–114.
Salot, P. (2013). A survey of various scheduling algorithm in cloud computing environment, International Journal of research and engineering Technology (IJRET), ISSN pp. 2319–1163.
Sindhu, S. (2015). Task scheduling in cloud computing, International Journal of Advanced Research in Computer Engineering Technology 4.
Sviji, K. M. A. (2016). Resource managment system in cloud environment: An overview, International Journal of Advanced Research in Biology, Engineering, Science andTechnology2: 357–362.
Tilak, S. and Patil, D. (2012). A survey of various scheduling algorithms in cloud environment, International Journal of Engineering Inventions 1(2): 36–39.
Topcuoglu, H., Hariri, S. and Wu, M.-y. (2002). Performance-effective and low-complexity task scheduling for heterogeneous computing, IEEE transactions on parallel and distributed systems 13(3): 260–274.
Vinothina, V., Sridaran, R. and Ganapathi, P. (2012). A survey on resource allocation strategies in cloud computing, International Journal of Advanced Computer Science and Applications 3(6): 97–104.
Warneke, D. and Kao, O. (2011). Exploiting dynamic resource allocation for efficient parallel data processing in the cloud, IEEE transactions on parallel and distributed systems 22(6): 985–997.
A Appendix: Configuration Manual
To perform this experiment, Eclipse and WorkflowSim are need to be installed on system. Steps to perform this experiment are as follows:
- Download and Install Eclipse on to the system.
- Download WorkflowSim simulator.
To import workflowsim into Eclipse, Open Eclipse and create new Java project named WorkflowSim.
Then right click on newly created project workflowsim and go to the Properties – Java Build Path – Source – Link Source
Then browse and select the examples folder from the downloaded workflowsim folder. Click on Next and Finish button.
Again click on ”Link Source”. Browse and select sources folder from the downloaded workflowsim folder. Click on Next and Finish button.
Again go to Properties of newly created java project workflowsim – Java Build Path – Libraries – Add External JARs. Then add all jars from the lib folder of downloaded workflowsim and click on OK.
- WorkflowSim is now ready for development and testing of scheduling algorithms.
- Then implement Proposed algorithms in Java.
Test implemented proposed algorithm by using different workflows such as Montage50, Montage100, CyberShake30, CyberShake50, Inspiral50.
- All the workflows are available into WorkflowSim-1.0 – config – dax folder.
Generated output contains Cloudlet Id, Status, Data center Id, VM Id, Time, Start time, Finish time, depth and makespan.
Proposed algorithm tests 10 times with each workflow and all the 10 outputs stores into separate excel file to calculate the median of all generated makespan. Median is the makespan of tested algorithm for the selected workflow.
Compare performance of proposed algorithm with MaxMin and FCFS based on the generated results.
Cite This Work
To export a reference to this article please select a referencing stye below:
Related Services
View all


Related Content
All TagsContent relating to: "Computing"
Computing is a term that describes the use of computers to process information. Key aspects of Computing are hardware, software, and processing through algorithms.
Related Articles

DMCA / Removal Request
If you are the original writer of this dissertation and no longer wish to have your work published on the UKDiss.com website then please: